Searchable Client-Side Encrypted Databases
April 19, 2026
The amount and size of data breaches seems nowhere near to plateauing. We do have the tools available, so this might be a question of education and sensibility. The Equifax CEO, when questioned in front of Congress after their 2017 breach, didn’t even know whether their data was encrypted at rest.
Despite this being laughable, do you even know which encryption mode you are using when hosting files on Dropbox, Google Drive, or AWS S3? In this model, as opposed to platforms like Facebook or Equifax, you own your own data, and are able to use client-side encryption as opposed to relying on the platform storing and managing keys properly for you. This is much safer, and recommended when available.
One can trivially encrypt files locally and drop them on the cloud, the only issue is that this loses advanced searchability, such as searching through photos or documents by keywords or tags. One can build indexes locally and keep them private, but this can become unwieldy very fast, as it grows and takes more storage, or if you want to have access to the same abilities on different devices. This article will focus on modern techniques to build such client-side encrypted datastores that don’t reveal anything to the server, while still retaining some form of efficient queryability.
Problem Setting
Searchable encryption solves the outsourcing problem: one party delegates storage to an untrusted server while retaining search capability. The client holds all the keys. The server is honest-but-curious — it follows the protocol but tries to learn what it can from the data it sees. We trust it for availability and integrity (correct execution), not for confidentiality. We could additionally turn the indexes into authenticated data structures to get integrity proofs and only need to trust the server for availability, but that’s orthogonal to the search problem and would warrant its own article.
Our setting rests on four constraints: one structured problem (search), over a static dataset, with one secret holder, and trust only in math. We exclude anything that relaxes any of them, which includes all the fancy stuff that the blockchain privacy space talks about: ZK, MPC, FHE, and TEEs (1, 2, 3):
- Generic computation. Our schemes exploit the specific structure of search (keyword lookup, range comparison, set membership) to build solutions that are orders of magnitude cheaper than general-purpose alternatives. FHE was briefly mentioned and can trivially solve encrypted search by evaluating an arbitrary search circuit homomorphically, and MPC can do the same through interactive secret-sharing protocols, but their generality is exactly why they’re impractical for this purpose.
- Static datasets. The client encrypts the dataset once, uploads it, and then only searches. We don’t cover dynamic operations — inserting, deleting, or updating documents after the initial upload. Dynamic schemes introduce their own leakage classes (forward/backward privacy), touched on briefly in Leakage Types.
- Multiple secret holders. Our model has a single client who holds all the keys. The server never contributes a secret input — it just mechanically evaluates tokens. A different class of problems arises when both parties hold private inputs that must be combined without revealing either one. Private set intersection (used by Signal for contact discovery), password authentication (OPAQUE), and Privacy Pass (blind-signed authorization tokens) all require interactive protocols where the server contributes keyed cryptographic operations. These are typically built from OPRFs and MPC primitives. They solve fundamentally different problems from outsourced search: the interactivity isn’t incidental, it’s inherent.
- Trust beyond crypto. Trusted execution environments (TEEs) can solve encrypted search efficiently — code runs at near-native speed inside a hardware enclave. But the guarantee shifts from mathematical proof to hardware trust: you’re relying on Intel or AMD’s implementation being correct and side-channel resistant, which has been violated repeatedly.
ZK proofs solve a different problem entirely: proving statements about data without revealing it (verification, not search). You could bolt ZK onto an encrypted search scheme to prove the server executed correctly, but ZK alone doesn’t help you find documents.
Encrypted Indexes
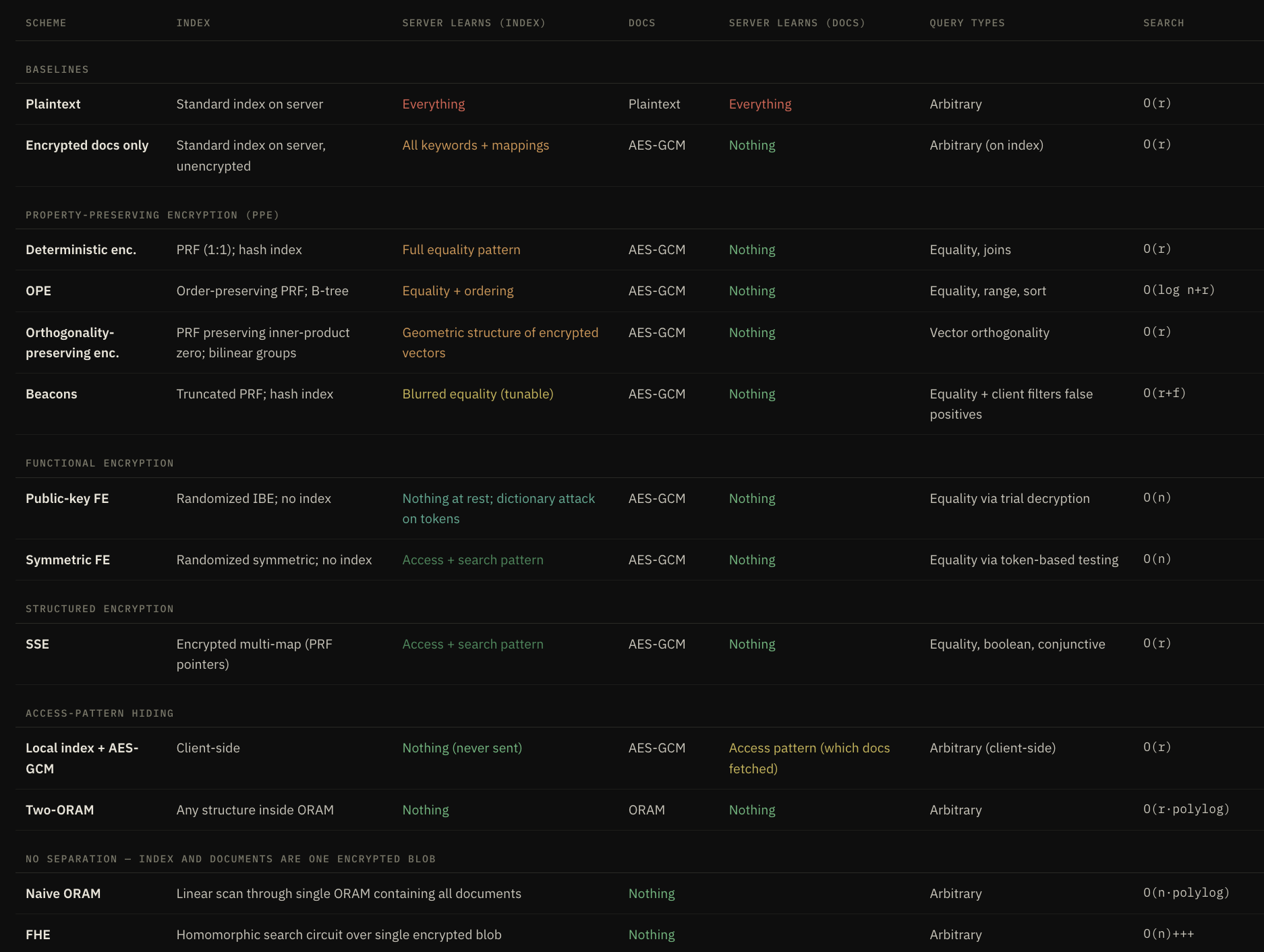
We will mostly be following the old but still very relevant series of articles How to Search on Encrypted Data, written by Seny Kamara and Tarik Moataz who have been leading the field of Searchable Symmetric Encryption and are currently leading MongoDB’s Queryable Encryption product. My goal is not to go into the details of any of the individual schemes, but rather to give a high-level architectural perspective to help people understand the differences without getting bogged down by too many low-level details.
Every encrypted search scheme makes the same architectural split: documents are encrypted with standard randomized encryption (AES-GCM or similar), and all the interesting cryptography goes into the index — the structure that enables search without decrypting everything.
Schemes
We will evaluate the schemes along three properties:
- Security measures what the server can learn, both at rest (passive leakage from the stored index) and during queries (access pattern, search pattern, query content)
- Efficiency is the server-side and client-side cost per query, as well as bandwidth used
- Query expressiveness is what types of queries the index supports: equality, range, boolean, or arbitrary computation
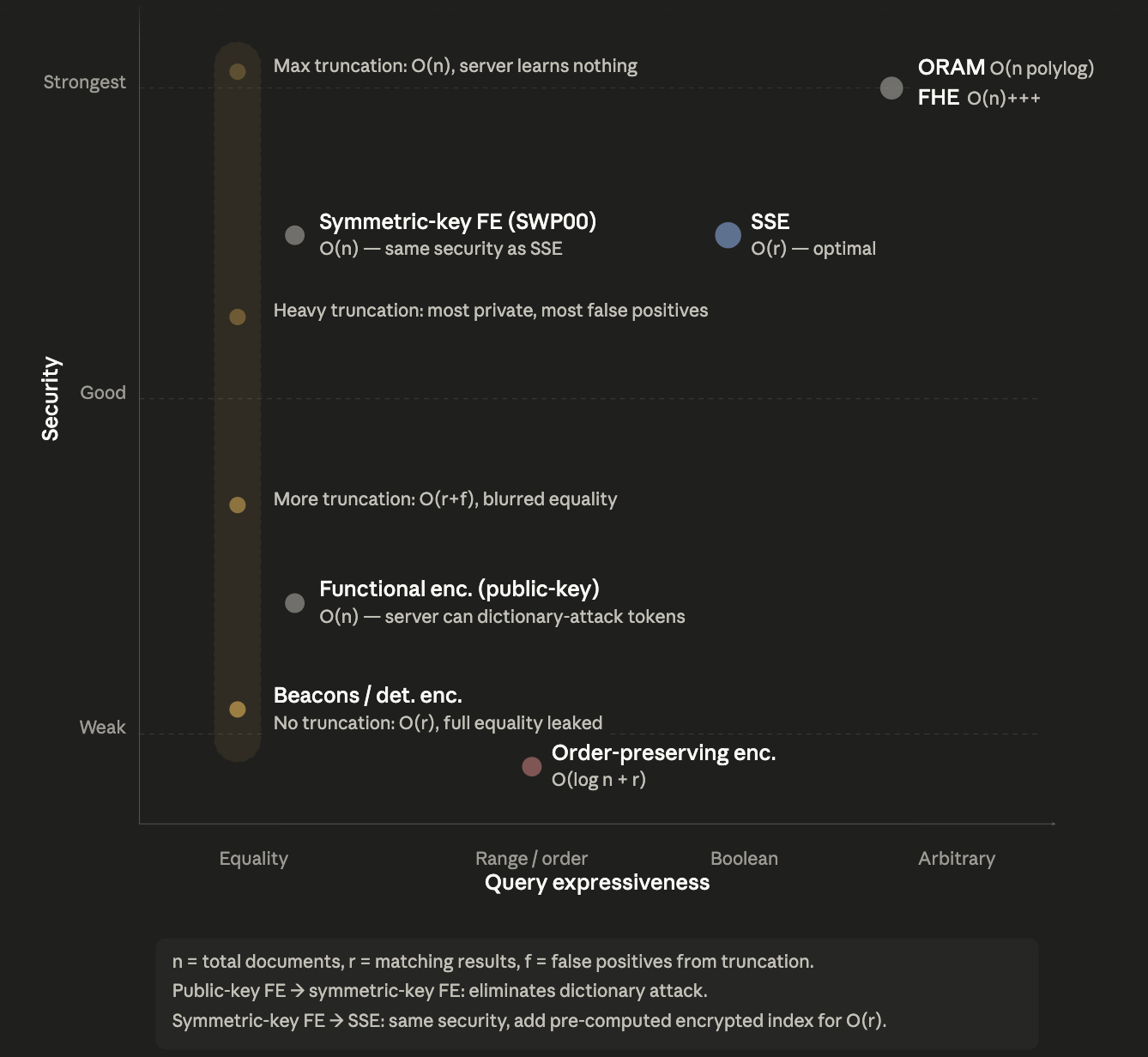
The schemes fall into four categories:
- Property Preserving Encryption (PPE) (order-preserving encryption, PRF-based deterministic encryption, beacons) give the server comparable entries, enabling fast standard indexes but leaking structure.
- Randomized schemes (symmetric and asymmetric FE) make entries incomparable, leaking little, but they prevent indexing and thus force O(n) scans.
- ORAM and FHE based indexes go further and hide even the query patterns, but at even worse cost.
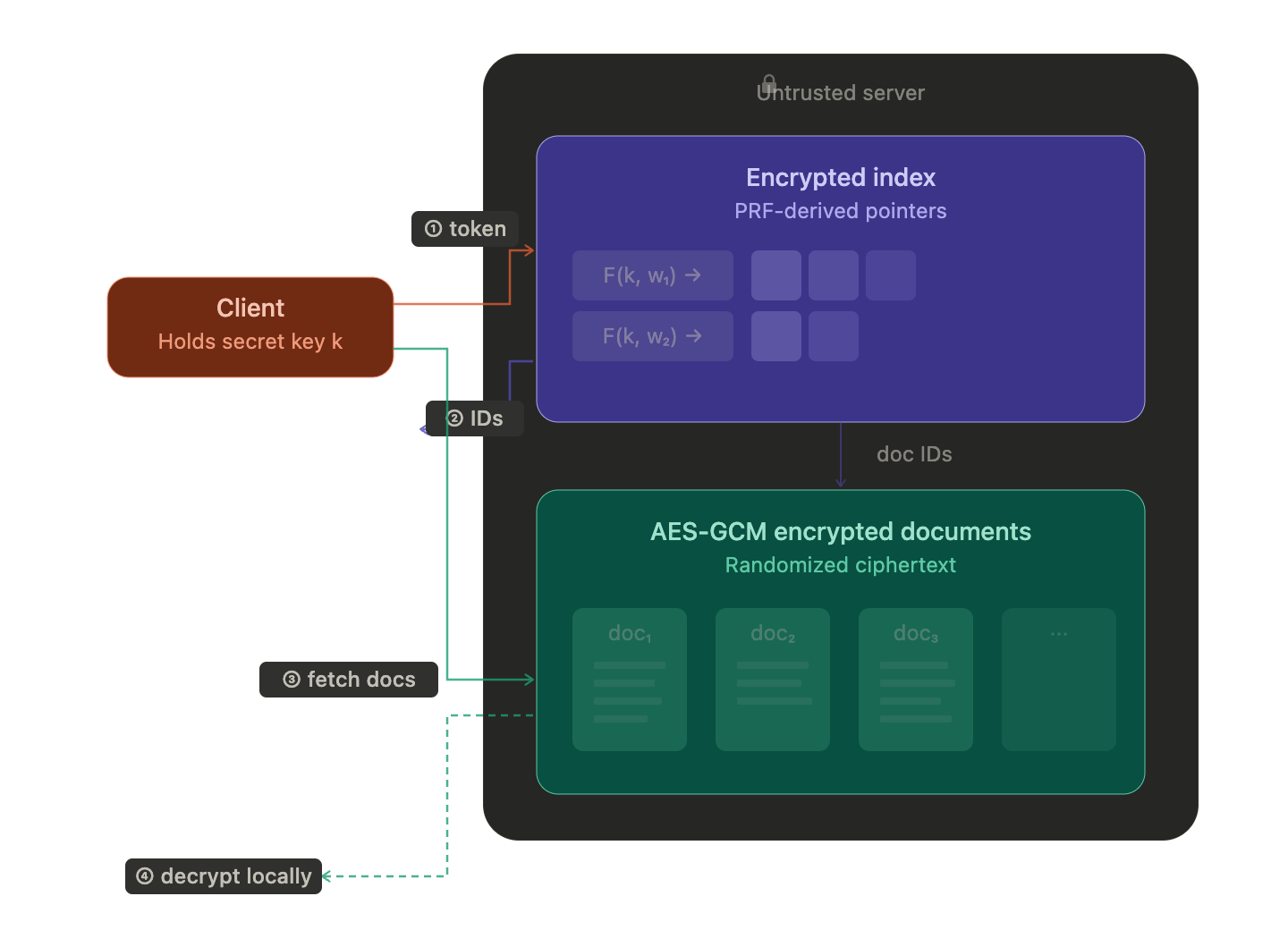
- SSE is the breakthrough that builds an encrypted index the server can traverse efficiently without being able to compare its contents, achieving O(r) search with formally characterized minimal leakage.
In more detail:
Baseline
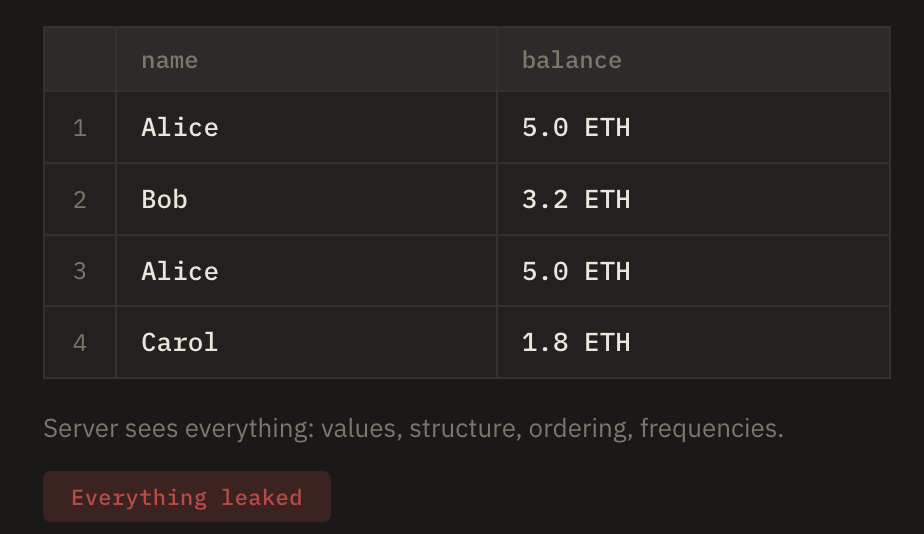
In plaintext, the server holds a standard index and the raw documents — it can see everything and answer any query at O(r) cost. The first step toward privacy is encrypting only the documents with AES-GCM while leaving the index unencrypted. This protects document content but gives the server the full keyword-to-document mapping — it knows every keyword, which documents contain it, and can answer any query the index supports.
For simplicity of visualization, we will compare different schemes according to this simple database, where we treat each document as a single row of this super simple schema where users have a balance, and where we want to be able to query either by name or balance, and hence need to build an index for either.
Deterministic Encryption
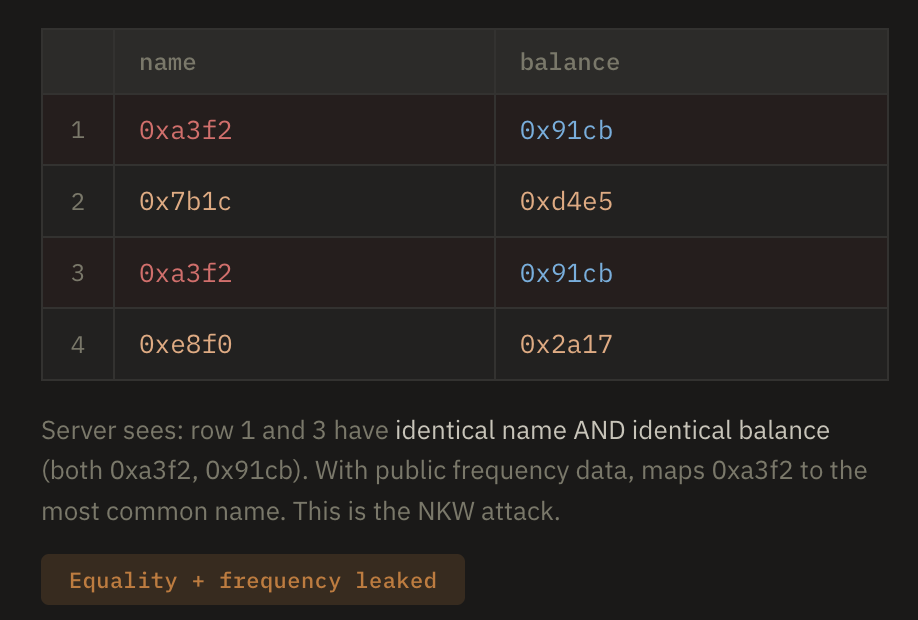
Deterministic encryption is the simplest encrypted index. Each keyword is encrypted with a PRF (or equivalently, a keyed hash like HMAC at full length), producing the same ciphertext every time. The server stores these in a standard hash index and does straightforward equality comparison. It’s fast and trivially compatible with existing databases, but the 1:1 mapping from plaintexts to ciphertexts means the server can see the full frequency distribution of every value — which keywords appear most often, which documents share keywords, and so on. This is the same structure that classical frequency analysis has exploited since the 9th century.
Note that in the visualization below, we treat the balance column as the index directly, as a typical SQL database like cryptodb would do. A more SSE-like encryption would treat the name and balance as an encrypted blob “document”, and then construct an extra index mapping the deterministically encrypted balances here to document addresses.
Order-Preserving Encryption
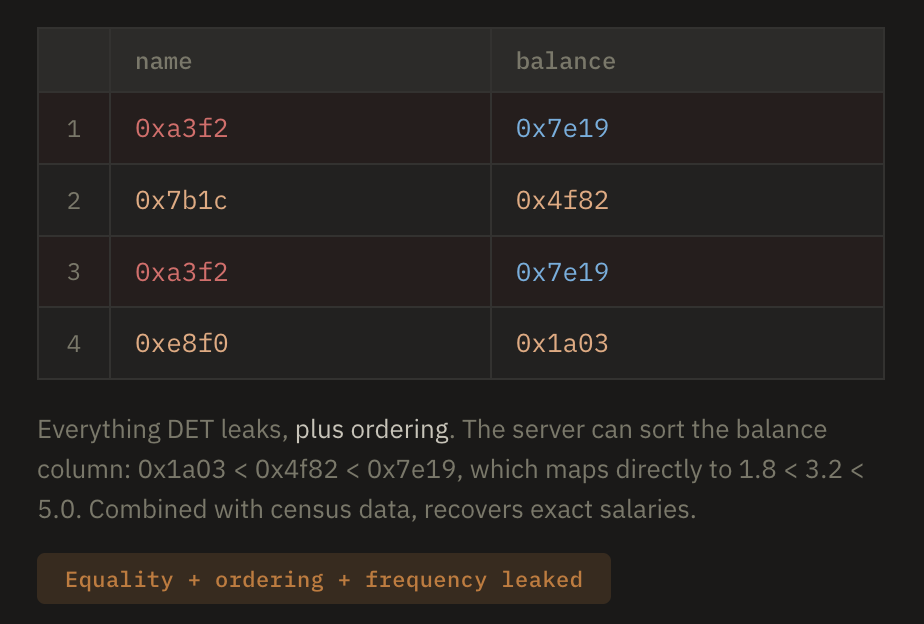
Order-preserving encryption encrypts values such that the ciphertext ordering matches the plaintext ordering: if salary A is greater than salary B, then Enc(A) is greater than Enc(B). This lets the server use a standard B-tree and answer range queries (WHERE salary > 50000) directly on encrypted data. The cost is severe: the server sees the complete rank ordering of every value in the column, which combined with publicly available auxiliary data (like census distributions) is often enough to recover plaintexts outright.
Orthogonality-Preserving Encryption
Orthogonality-preserving encryption extends the PPE idea to vectors. Given two encrypted vectors, a public test can determine whether their inner product is zero (i.e., whether they’re orthogonal) without decrypting either one. It is of course very powerful, but follow-up work cryptanalyzed the scheme and showed it doesn’t achieve even the weakest security notion — an attacker with a single query can extract significant information about unknown encrypted vectors.
Beacons
Beacons (truncated HMAC) use the same PRF mechanism as deterministic encryption but deliberately discard output bits. By truncating the HMAC to, say, 16 bits, many different keywords collide onto the same tag. The server can still do an O(1) hash lookup, but the result set contains false positives — records that matched the truncated tag but not the actual keyword. The client decrypts these candidates and filters locally.
It’s the same idea as k-anonymity: instead of your query pointing to exactly the 2 Alice rows, it points to a bucket of, say, 15 rows that includes Alice, Carol, and Dave. The server sees “someone queried bucket 0xa3” but can’t distinguish an Alice query from a Carol query. The more you truncate, the bigger the buckets, the more false positives, but the stronger the privacy guarantee.
The knob runs continuously between two extremes:
- No truncation (full HMAC) → bucket size 1 → zero false positives → server knows exactly which keyword → collapses to deterministic encryption
- Maximum truncation (1 bit) → bucket size ≈ n/2 → half the database returned → server learns almost nothing → approaching “just download everything”
![]()
Functional Encryption
Functional encryption (public-key, IBE-based) encrypts each keyword using a randomized identity-based encryption scheme, with the keyword as the identity and “1” as the message. Because fresh randomness is used per encryption, two encryptions of the same keyword look completely different — the server can’t build any index over the entries. To search, the client generates an IBE secret key for keyword w, and the server attempts decryption on every entry. Successful decryptions indicate matches. This costs O(n) but leaks nothing at rest.
The fundamental weakness is the public-key setting: since the server holds the master public key, it can encrypt a dictionary of candidate keywords and test any search token against them, recovering the exact keyword being searched. This problem is solved by using symmetric-key FE.
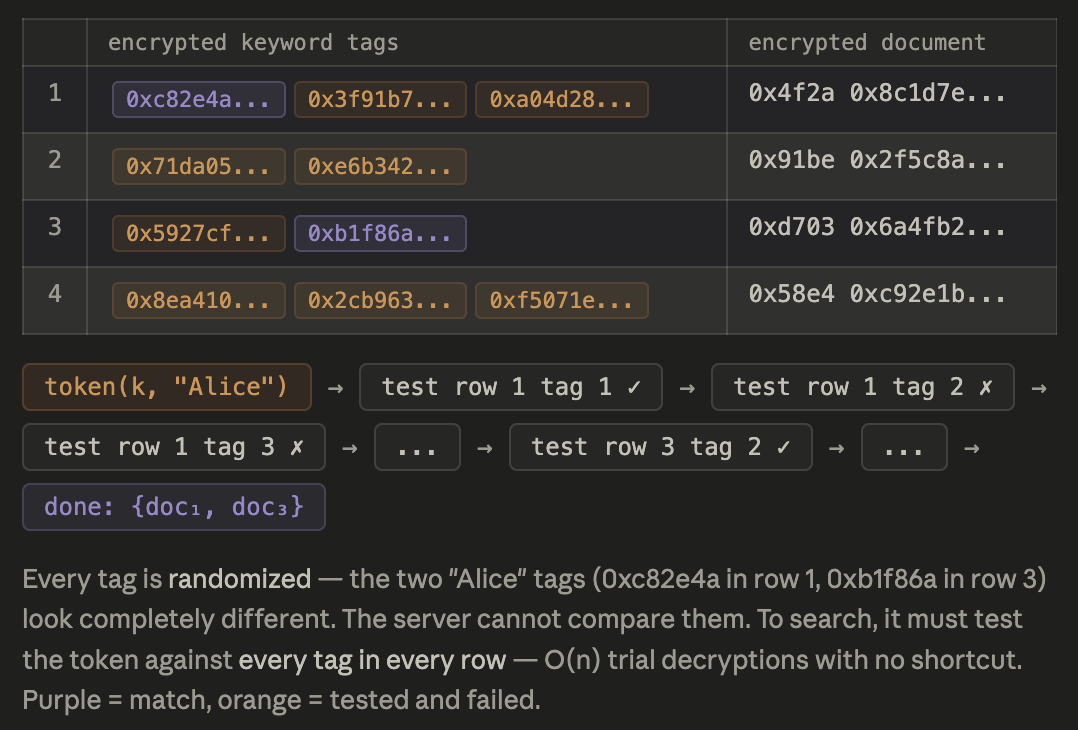
Symmetric-key Functional Encryption
Symmetric-key functional encryption was introduced and started the field of SSE. The client constructs encrypted keyword entries using a secret key, and search tokens allow the server to test each entry for a match. Because the server can’t generate its own ciphertexts (it doesn’t have the key), the dictionary attack that plagues public-key FE is impossible. The server learns which entries matched (access pattern) and whether the same query was repeated (search pattern), but not which keyword was queried. This gives it the same security profile as SSE, but at O(n) cost since there’s no pre-computed index to accelerate search.
Searchable Symmetric Encryption
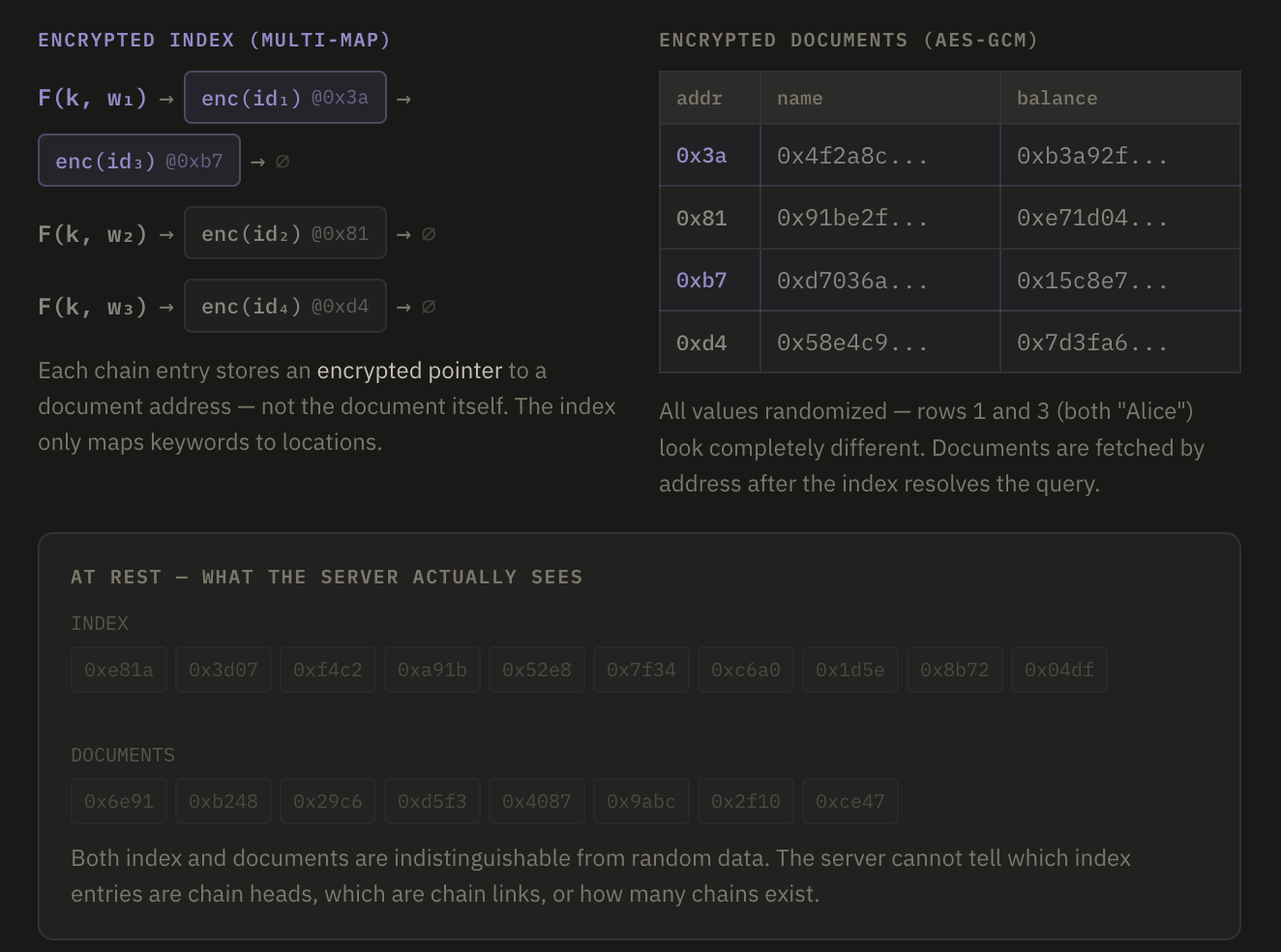
Searchable Symmetric Encryption (SSE) is a data-structure based optimization over the previous scheme. Instead of having to search over the entire tag column, SSE precomputes an encrypted multi-map, such that every token points to an encrypted linked list that returns the exact pointers to the documents that match the query. At setup time, the client builds an inverted index where each keyword’s matching document IDs are stored as an encrypted chain at pseudorandom locations derived from the PRF. A search token lets the server locate the start of the chain and follow it to collect exactly r results.
At rest, the index looks like random data. During queries, the server learns the access pattern and search pattern but not the query content. Note that this is the exact same security as that achieved by the previous scheme, while having the optimal O(r) query cost, only retrieving the exact r documents that match the query token.
Client-Side Index
One way to make sure that nothing except the result documents is leaked is to keep the index on the client, if that is feasible. The client resolves the query locally — the server never sees a search token, so index leakage is zero. But the client still needs to fetch the matching documents, and those fetches are visible. The server sees which document IDs the client requests (the access pattern), and over time can correlate which documents are frequently retrieved together.
One could store the documents in ORAM to prevent the server from learning which document gets retrieved, if that cost is acceptable.
Separate ORAM for index and docs
To put the index on the server without letting it learn everything, we need to place both in separate ORAM instances. The client queries the index ORAM to get matching document IDs, then retrieves those documents from the document ORAM. Because ORAM hides access patterns on both sides, the server learns nothing from either operation. The cost is O(r · polylog n) due to ORAM’s reshuffling overhead on each access, but the security is the strongest achievable with a separated index-and-documents architecture.
Note that putting only the index in ORAM while leaving documents as plain AES-GCM doesn’t buy you anything. The whole point of ORAM on the index is to hide which entries you’re looking up — but as soon as you take the resulting document IDs and fetch those documents from a non-oblivious store, the server sees exactly which documents you retrieved. That access pattern is precisely the information the index ORAM was trying to conceal. You’ve paid the ORAM overhead for nothing; the security degrades to the same level as a local client-side index with AES-GCM documents. To actually benefit from ORAM on the index, you need ORAM on the document store too — hence two-ORAM.
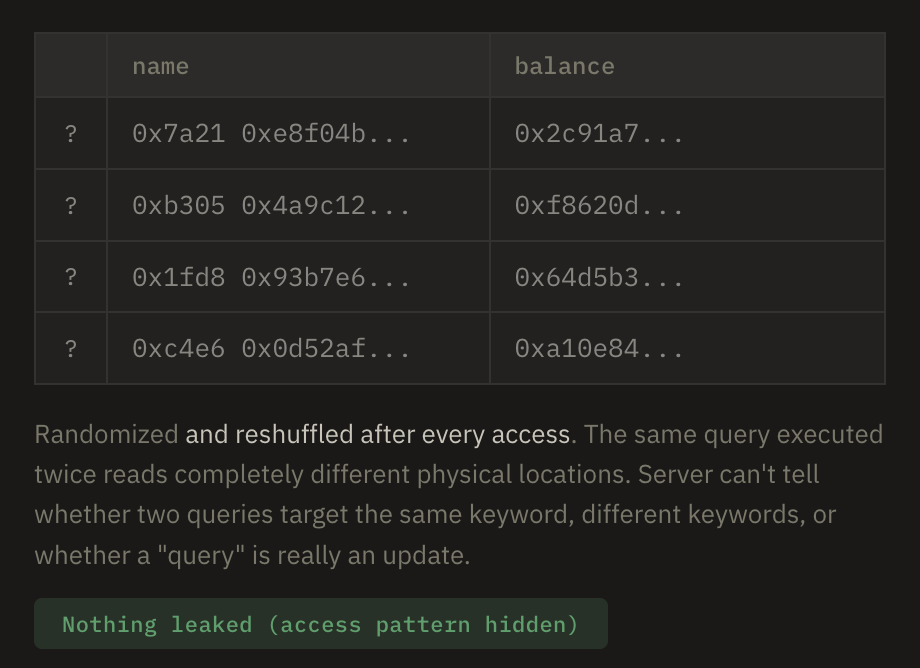
Combined ORAM
Combined ORAM abandons the index-documents separation entirely. The entire collection — documents and all — lives inside a single ORAM. To search, the client linearly scans through the ORAM, touching every block. The server learns nothing (ORAM hides even the scan pattern), but the cost is O(n · polylog n) per query since every document must be accessed regardless of how many match.
Note that this scheme is much more expensive than the separate ORAM schemes. Whether this is worth paying depends on whether volume leakage is important or not: in the separate scheme, a server will learn how many documents match a given query, whereas in the combined approach the server sees exactly n ORAM accesses every time.
The tradeoff is:
- Naive ORAM: O(n · polylog), hides everything including volume
- Two-ORAM: O(r · polylog), hides access pattern but leaks volume
- Two-ORAM + padding: O(max_r · polylog), hides everything but you’re back to paying for the worst case
Fully Homomorphic Encryption
Fully homomorphic encryption (FHE) also abandons the separation. The client encrypts the entire dataset under an FHE scheme, and to search, sends an encrypted query. The server homomorphically evaluates a search circuit over the encrypted data and encrypted query, producing an encrypted result that only the client can decrypt. The server learns absolutely nothing; not the data, not the query, not the result, not even the access pattern. The cost is enormous, however: every homomorphic operation introduces noise into ciphertexts, requiring periodic “bootstrapping” (homomorphic self-decryption) to keep noise levels manageable. In practice, even simple operations are orders of magnitude slower than their plaintext equivalents, making FHE-based search impractical for anything but small datasets or theoretical constructions.
Leakage Types
Every practical encrypted search scheme leaks something — the question is what exactly, and how dangerous it is. The foundational SSE work by Curtmola, Garay, Kamara, and Ostrovsky introduced simulation-based security definitions that make this precise: a scheme is proven secure with respect to a leakage function L, meaning an adversary interacting with the real system can be simulated by one that only sees L. This tells you exactly what’s exposed and nothing more — but it doesn’t tell you how bad that exposure is in practice. Cash, Grubbs, Perry, and Ristenpart answered that question by demonstrating concrete leakage-abuse attacks that exploit these formally characterized leakage profiles to recover queries and even plaintexts from real-world datasets. More recently, Kamara and Moataz proposed a Bayesian framework that bridges the two: modeling leakage profiles as Bayesian networks and bounding how much an adversary can infer given observed leakage and auxiliary information.
The leakage types below are ordered from most to least information revealed.
At rest (setup leakage):
- Database size: number of documents, total storage size. Basically every scheme leaks this — the server can see how big the blob is.
- Index structure: for PPE schemes, the server can compare index entries and learn equality patterns, ordering, frequency distributions — all without any queries happening. SSE and above leak nothing at rest (index looks random).
Per-query leakage:
- Volume pattern: how many documents matched. Strictly weaker than access pattern — you learn “12 documents matched” but not which 12. Even ORAM-based schemes can leak this unless you pad all results to a fixed size.
- Access pattern: which specific document IDs matched. Subsumes volume pattern. This is what SSE leaks.
- Search pattern: whether two queries target the same keyword. In SSE this comes from deterministic token generation — same keyword produces same (or recognizably related) token. This is independent of access pattern in principle, though as we discussed, one can often be inferred from the other. Similar to unlinkability.
- Query content: the actual keyword itself. PPE schemes effectively leak this (deterministic encryption lets the server build a reverse lookup over time via frequency analysis). FE with public keys leaks this via dictionary attacks. Schemes above SSE don’t leak query content directly.
Intersection/correlation leakage (derived across multiple queries):
- Intersection pattern: which documents appear in the results of multiple different queries. Over time, the server builds a co-occurrence matrix. This isn’t a separate leakage mechanism — it falls out of observing access patterns across queries — but it’s what makes access pattern leakage so dangerous in practice, because it enables the inference attacks.
- Frequency analysis: observing how often each token appears lets the server match encrypted tokens to likely keywords using known-distribution attacks.
Dynamic leakage (for schemes supporting insert/delete):
- Forward privacy: when a new document is added, can the server learn which previous search tokens it would have matched? If yes, the server retroactively learns that keyword
wwas searched before and this new document contains w. Forward-private SSE schemes prevent this. - Backward privacy: when a document is deleted, can the server learn it was previously in some query’s result set? This comes in several grades depending on exactly how much history leaks.
PPE leaks almost everything including query content (via frequency analysis). FE and SSE eliminate query content and at-rest leakage but still leak access and search pattern. Two-ORAM eliminates access and search pattern. Combined ORAM and FHE eliminate everything including volume pattern (the server can’t even tell a query happened — it just sees a homomorphic computation).
The one annoying leak that’s hardest to kill is volume pattern — even with two-ORAM, if the client makes r reads from ORAM₂ after querying ORAM₁, the server can count r. You need explicit padding (always fetch a fixed number of documents regardless of actual matches) to hide it, which most practical schemes don’t bother with.
As for forward and backward privacy, those are only relevant in dynamic schemes which allow inserting, updating, and deleting documents, which were not the focus of this article. Production systems like MongoDB’s Queryable Encryption must contend with these obviously, but we kept this article focused on the static case for clarity of exposition.
References
- How to Search on Encrypted Data: Introduction (Part 1) — Brown ESL blog
- Database Cryptography Fur the Rest of Us — Soatok
- Encrypted Search (book chapter) — UCI
- Public Key Encryption with Keyword Search — Boneh et al., Stanford
- SQL on Structurally-Encrypted Databases — IACR ePrint 2016/453