Config DSLs: are we there yet?
September 13, 2025

The 12 factor app approach has taught a generation of programmers to maintain strict separation of config from code. It went further and even prescribed apps to keep their config as simple env var key-value pairs!
That approach might have worked for simple Heroku web-apps of the day, but a single namespaced flat config file is clearly not the right way to manage large scale systems.
We’re in 2025, and misconfiguration is still the largest source of production large-scale bugs. Rust made its way as the top-of-chain safe programming language. Is there a safe config language that can do the same for devops? Bicep, CUE, Dhall, Json-e, Jsonnet, KCL, Nickel, Pkl, Starlark have all proliferated to try to solve this problem.
Config Complexity Clock
As a system grows, typically so does its feature set and related configuration: see google chrome’s 1400 CLI flags for a scary example. Most seasoned devops engineers are likely familiar with the configuration complexity clock; if not by name then no doubt at least by concept.
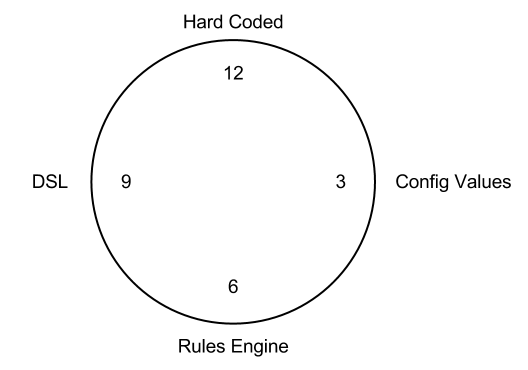
My own personal experience has seen projects progress a slightly different but very related manner (rules engine are not a thing that I’ve ever worked with…):
- magic numbers in code
- magic numbers become named consts
- consts turned into configurable variables, ingested via flags, env-vars, or a flat config-file
- config values grouped into categories using key prefixes (
SERVER_X_Y_Z,STORE_X_Y_Z, etc) - flat config turned to json for hierarchical namespacing
- json converted to proper hierarchical config format (yaml, toml, hcl) as some dev gets tired of not having comments (json is a data transport format; not a config language)
Most projects would be better off stopping the pendulum at this 6 o’clock position, immediately closing all issues related to configuration improvements, and spending their time on more useful things (downscope and go-to-market anyone?). However, it requires a very seasoned and right-curved tech lead to prevent the complexity demon from hitting their project’s config. The fact that the grug brain manifesto does not contain a section on KISS’ing one’s config file is still bewildering to me.
Because of the multitude of different safe config languages out there, an analogy more apt than a complexity clock to me is a complexity pendulum. If you ever enter this pendulum, you are forever stuck oscillating back and forth between different extremely complex solutions that each have tradeoffs, with none having yet matured to a scale of industry wide adoption. CUE feels like it might have the best chance at being the “rust of config files”, but its clearly still got a long way to go. You’ve now been warned… so let’s now set this perpetual pendulum in motion, shall we?
DSL Config Pendulum
If the devil is in the details, then make sure to have as few details as possible.
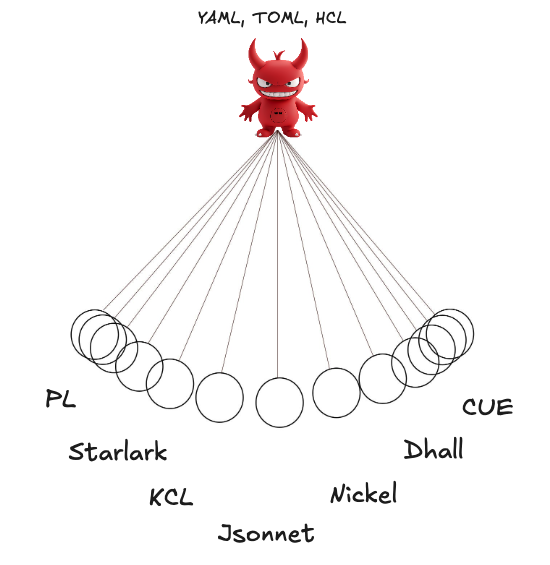
Here goes the config pendulum, swinging back and forth in a never ending smooth perpetual motion, driven by the incessant dissatisfaction of big brained developers, and the search for a tool to solve all devops issues once and for all:
- read borg paper, listen to signals and threads, move config to same language as code
- read google SRE book’s pitfall #5, realize turing-completeness is bad, move to starlark (to remain in imperative language)
- miss having types, move to KCL
- get bitten by inheritance; gives up on types and tries the SRE book’s suggestion to use Jsonnet
- gets hurt by runtime misconfiguration bugs, realizes doesn’t have google level of tooling and testing, move to typed Nickel
- want dependent types to encode security guarantees between code and config, move to Dhall
- realize a very small subset of dependent types (lattices containing both values and types) might be the holy grail, move to CUE
- miss programming language level of tooling, return to 7
Why do we need any of these config DSLs?
The goal of this article is not to go into great detail about any of the complex languages listed above, but rather to help the reader develop a framework for realizing how closely related each of them are, and how they are trying to solve a similar problem: that of safely generating (programatically!) configuration data. To programatically generate configuration data, we need a configuration language.
Following the SRE book’s configuration design chapter, a system is composed of:
- code, which is parameterized by
- configuration data, and processes
- user data (input -> output)
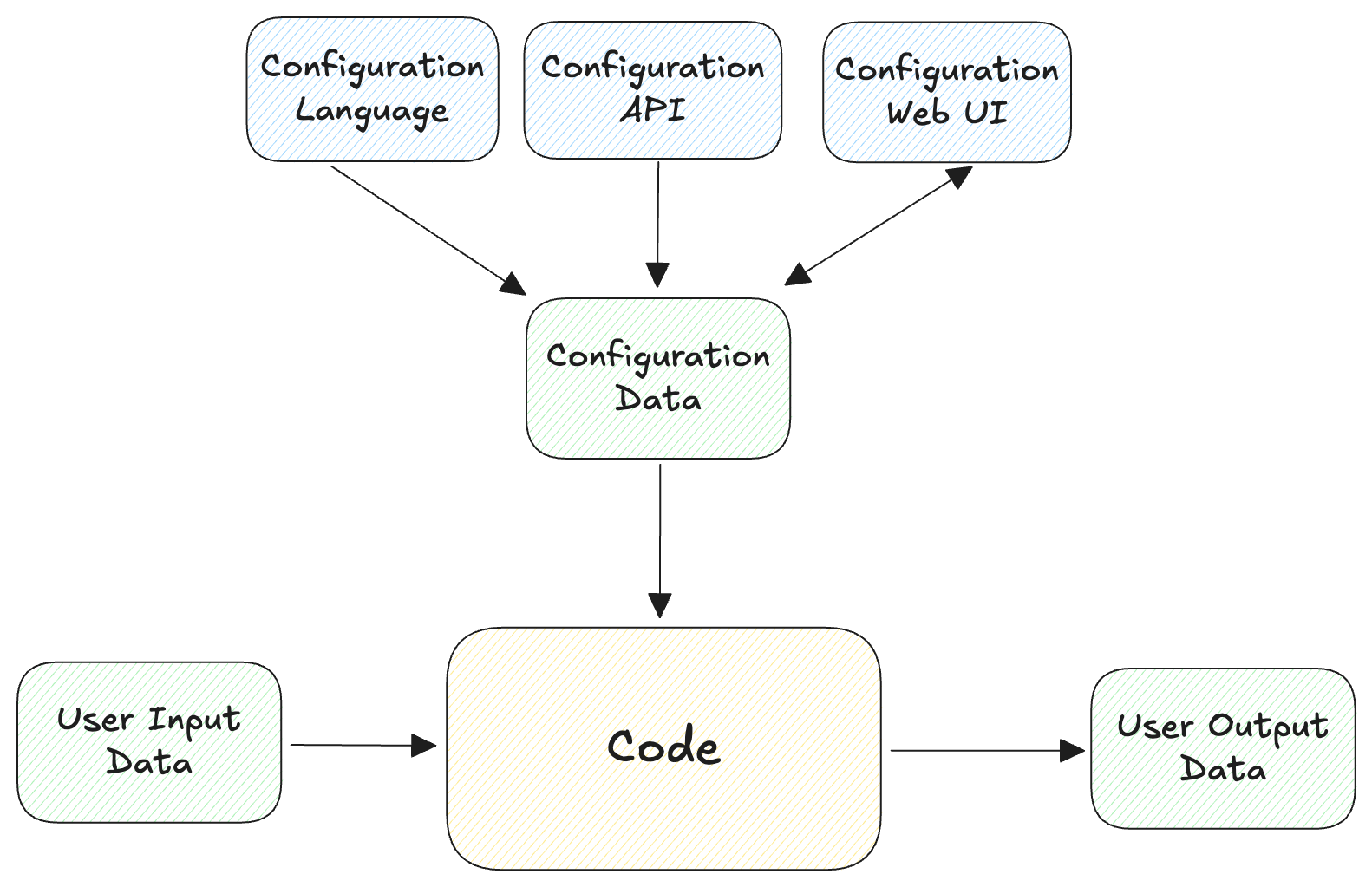
The languages above are all “configuration languages”, which can effectively be thought of as different ways to (safely!) generate configuration data (json, yaml, toml).
The “Borg, Omega, and Kubernetes” paper also argues
[…] configuration management systems tend to invent a domain-specific configuration language that (eventually) becomes Turing complete, starting from the desire to perform computation on the data in the configuration (e.g., to adjust the amount of memory to give a server as a function of the number of shards in the service). The result is the kind of inscrutable “configuration is code” that people were trying to avoid by eliminating hard-coded parameters in the application’s source code. It doesn’t reduce operational complexity or make the configurations easier to debug or change; it just moves the computations from a real programming language to a domain-specific one, which typically has weaker development tools such as debuggers and unit test frameworks. We believe the most effective approach is to accept this need, embrace the inevitability of programmatic configuration, and maintain a clean separation between computation and data.
The above quote describes option 7 in the pendulum. However, many authors of that paper have moved on from that perspective, and swung back to the config DSL approach. Marcel van Lohuizen who invented CUE was on the initial Borg team and created GCL. He argues using the below diagram for why full fledged programming languages shouldn’t be used to generate configuration data:

In order to be read, understood, and modified by a different team during the face of an emergency, a lot of restrictions need to be placed on that language! And that is the essence of why new languages are needed for safe config languages, and why a language like rust can’t be reused.
What makes these DSLs safe?
For a config DSL to be safe, it needs a type system and certain restrictions. The different languages above can all be described by:
- the expressivity of their type system: simple types, ADTs, dependent types, etc.
- the restrictions they place on users: turing (in)completeness, inheritance, etc.
Nix is a great case study for the need for both of these, as well as why they need to be codesigned from the get-go! Here is a snippet from the original Nix paper:
Rather than having specific builtin language constructs for these notions, the language of Nix expressions is a simple functional language for computing with sets of attributes.
Twenty years of organic language and community growth later, and what we observe in practice is that programmers actually self-imposed constraints in order to be able to program in the large (not unlike Javascript: The Good Parts):

These have more to do with package manager level of features, composition, inheritance, etc. When doing config programming in the small, the main constraint that is typically removed turing completeness (though see this for why turing incompleteness is not restrictive enough). The main examples here are Starlark, CUE, and Dhall. These have been properly designed from the start with a “programming in the large” approach, such that they won’t fall victim to every simple (config) language will eventually end up turing complete.
Applying the above classification to our config DSLs, we get:
| DSL | Type System | Turing Complete | Inheritance | Key Constraints/Features |
|---|---|---|---|---|
| CUE | Structural typing with constraints | No (terminates by design) | Via embedding/composition | Constraint-based validation; values are types; no recursion |
| Dhall | Strong static typing with dependent types | No (total functional language) | Via type-level composition | Guaranteed termination; no recursion; immutable; type-safe imports |
| Jsonnet | Dynamic typing with runtime checks | Yes | Object-oriented inheritance | Full programming language; mixins; late binding; can be unsafe |
| KCL | Gradual static typing | Limited (restricted computation) | Schema-based inheritance | Constraint validation; immutable; no side effects; bounded recursion |
| Nickel | Gradual typing with contracts | Limited (restricted recursion) | Via merging/composition | Contract-based validation; functional; controlled recursion depth |
| Pkl | Static typing with generics | Limited (safe computation model) | Class-based inheritance | JVM-based; immutable; no arbitrary loops; Apple-developed |
| Starlark | Dynamic typing | No (restricted Python subset) | Limited (no classes) | Deterministic; no I/O; no recursion; used by Bazel/Buck |
Cue
Cue’s main value proposition is outlined by its creator in this answer (the whole answer is worth reading, but here’s the first paragraph):
CUE was developed as an answer to the pitfalls of GCL (very much like Jsonnet). See the discussion in https://cuelang.org/docs/usecases/configuration/. It is based on an 30-year old approach from NLP, where it was used to model large 100k lines up configurations (grammars and lexicons), maintained by distributed groups of teams.
TLDR is that Cue is a logic constraint-based language, where constraints are types and live in the same lattice as values. Its the formalization of safe config data composition. Think of dependent types if you know what those are, but much much more constrained, to fit the needs of large scale config management, meaning constrained inheritance.
I honestly wish CUE was the end of the safe config language war. Reading about it sure feels like it is. But it’s too early to tell, I personally don’t have enough experience with it, and it isn’t used in enough large scale systems to have proven itself. One thing I fear is that it will remain niche and worse is better will have the better of it.
Will these languages generalize beyond Config Management?
Some of these languages might be vying for a broader impact than just configuration. An important question that remains to be solved is whether the restrictions placed on these languages for solving config management issues will also be of use in other parts of application lifecycles. Can the same typed “json with functions” DSLs be used for:
- Infra deployment (IaC): terraform HCL
- System Package Manager (find dependencies): nix
- language package managers tend to use simple package:version key:value pairs + SAT solver
- Build System (make, bazel)
- CICD/Integration-Testing: GHA, dagger, kurtosis
- App deployment (k8s yaml, kustomize, jsonnet, etc)
- App config itself (this article)
- Orchestration: Workflow (code) vs AWS Step (json data)
Or will we need to learn a separate language for each of these specialized tasks? Only time will tell. I’m really hoping a “kubernetes of config management” will emerge and become standard.