Doublezero: what is it good for?
August 22, 2025
In May 2022, Victor Shoup analyzed the Solana whitepaper and wrote Proof of History: what is it good for? His answer: not much. Three years later, Solana no longer uses proof of history.
This blog post is an amateur attempt to follow in Shoup’s footsteps, this time analyzing the DoubleZero protocol, based on their whitepaper, articles and public docs (their github is mostly empty). My conclusion after a week of research is not nearly as dire, and I am extremely excited by the project. That being said, I am unconvinced by their Proof of Utility economic primitive and feel that it needs a lot more research. Given that Shoup is a consensus expert, whereas I am neither a networking nor an economics expert, I will leave the followup article “Proof of Utility: what is it good for?” for someone else to write. With that out of the way, let’s dive in.
What is DoubleZero?
DoubleZero works across multiple planes, but the very succinct take is that it’s a blockchain CDN, attempting to be a decentralized and marketplace driven Cloudflare alternative for blockchain content filtering and low-latency low-jitter delivery. It is developing its own IXP(s) to allow large validator and network connection providers to peer and communicate over faster multicast lanes. It’s also developing its own FPGA implementation for edge filtering of transactions.
We will analyze these claims in more details, diving into the implementation details that are available, and questioning whether this network makes sense economically. But first, let’s start by answering the five Ws.
Who?
DoubleZero was started by three cofounders:
- Austin Federa (CEO?): previous head of communication at Solana labs.
- Andrew McConnell (CTO?): previous team lead of US Trading Infra @ Jump, and long time ago 1 year at NASDAQ.
- Mateo Ward (COO?): founder of Neutrona Networks, an SDN-based ISP serving latin america, which was acquired by Transtelco in 2020 for an undisclosed amount.
What?
- Architecturally made up of an outer ingestion+filtering ring, and an inner consensus+execution data propagating ring (see picture below)
- Consensus participating validators are supposed to run the hardware and service for both rings:
- outer: FPGA running deduplication, filtering, and signature verification of txs
- inner: latency minimizing multicast routing, currently running over GRE
- Policy/Product-wise, DZ is a market for leasing underutilized private links and sharing infrastructure, with SLAs registered on a Solana smart contract (but unclear how they are enforced…).
The whitepaper is very low on protocol details, but their architecture docs contains a useful diagram.
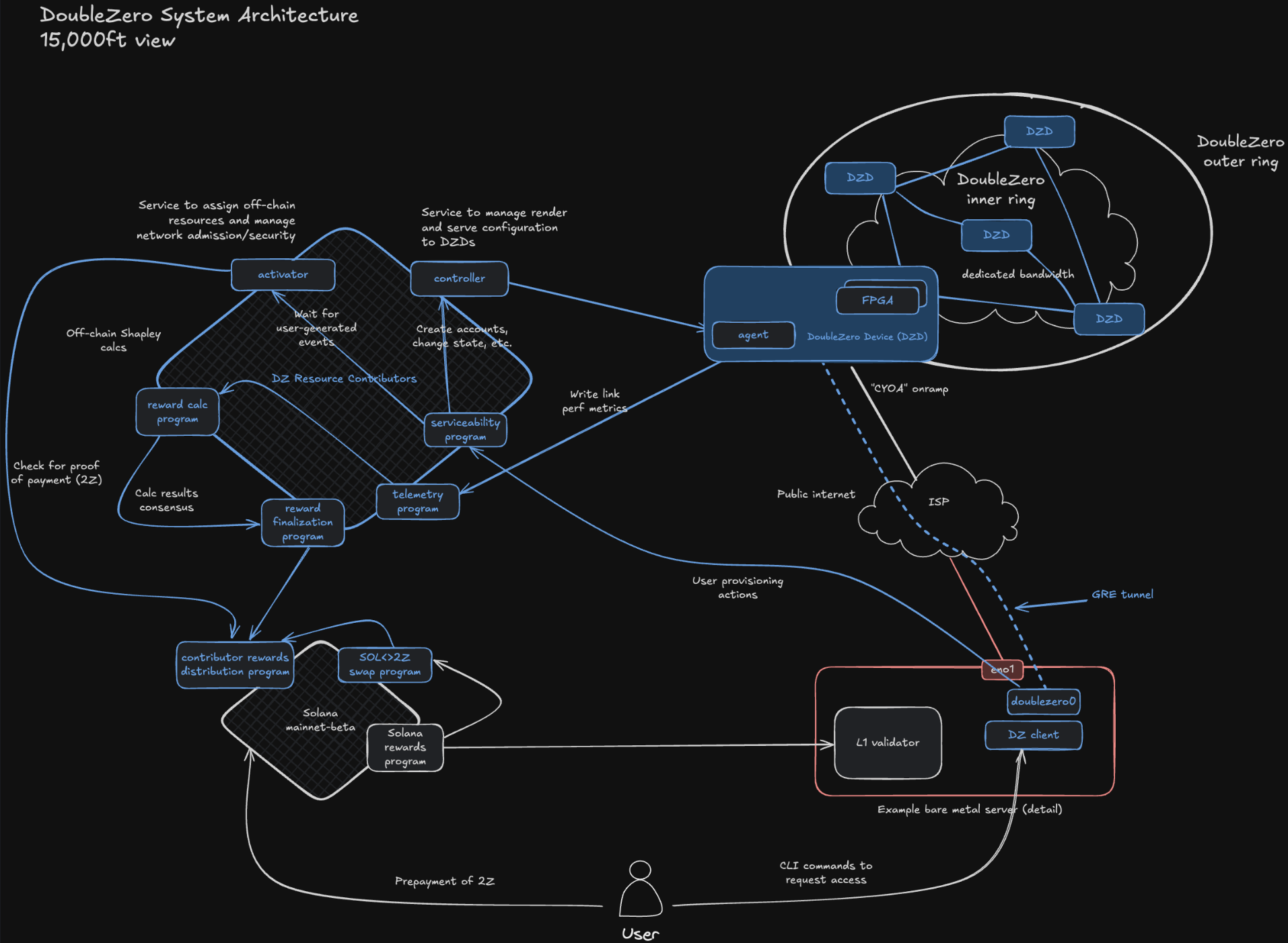
Their docs also mention:
Your host firewall must allow inbound GRE (IP protocol 47) and BGP (TCP port 179)
I have not read their (surprisingly fairly detailed) contributors docs in full details, but my current understanding is that they use GRE for tunneling ip multicast packets between the different doublezero users (solana validators). Most internet routers drop ip multicast (IGMP and PIM) packets, so it is necessary to tunnel them between the various datacenters where l2 or l3 multicast is supported. Multicasting is completely standard in the financial industry, so it makes sense for it to be used as the doublezero networking primitive.
Where?
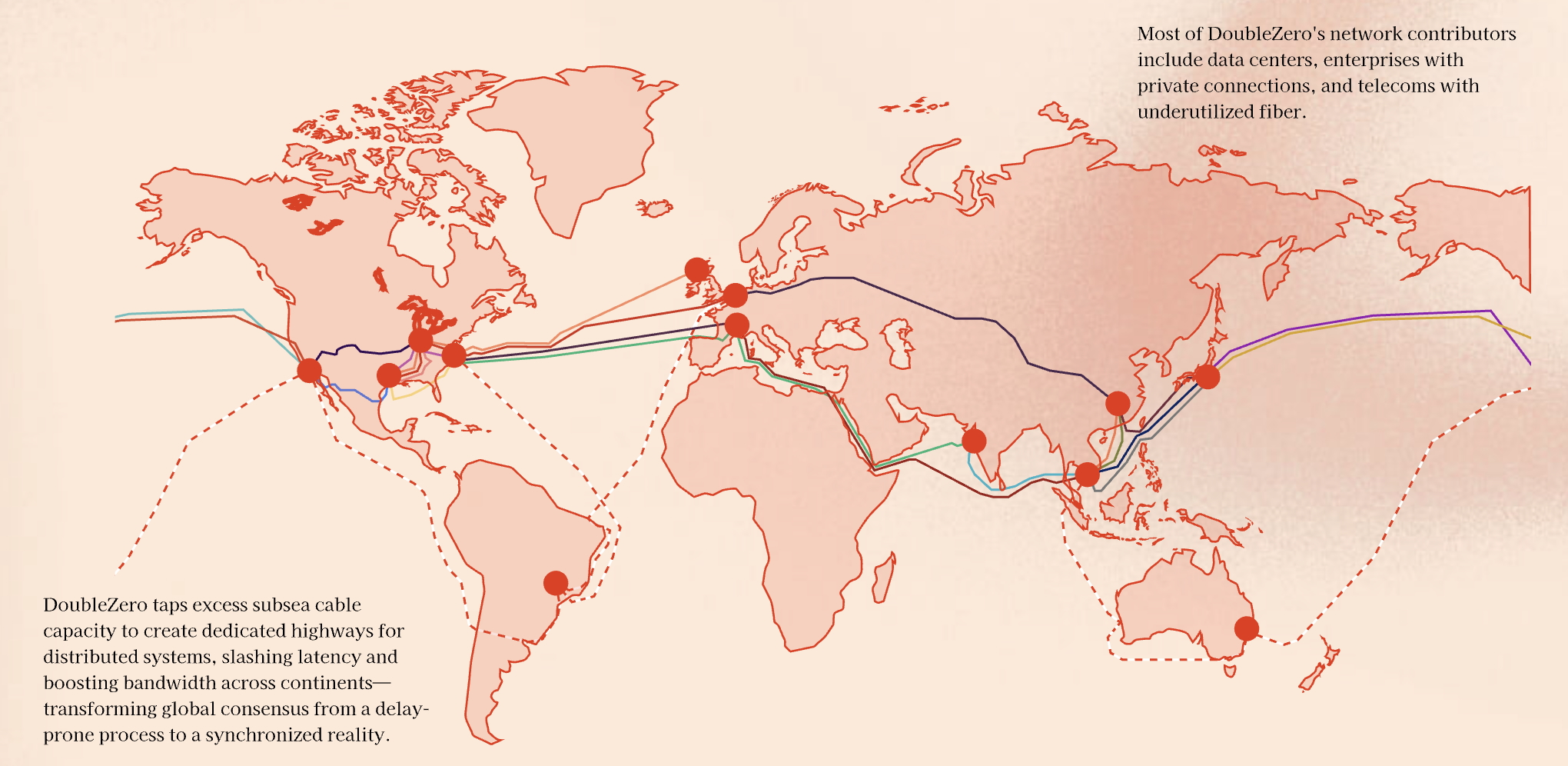
They run a (currently permissioned) testnet with routes connecting major validator datacenters around the world. Have not checked the accuracy of the below map found on their website.
When?
If wen token, a validator token sale happened last April, but no token has been launched yet.
If wen mainnet, its apparently soon.
Why?
There are a lot of why questions that come to mind when thinking of DoubleZero. Their docs state 2 benefits:
- “inbound transactions can be edge-filtered in a non-discretionary way at the network contributor hardware level (i.e. removal of spam and duplicates) prior to being sent over to users (e.g., blockchain nodes) of the DoubleZero network.”
- “outbound messages are routed more directly and prioritized to improve efficiency.”
These are clear benefits for users (validators) of the DoubleZero network. But given that DoubleZero is a marketplace, we must also answer why people would the other side of the market participate. Why would contributors (of network capacity and possibly FPGA hardware) provide their resources to the network? The short term answer is clear: for token incentives. Whether this economic model can make sense at equilibrium I have doubts, which we will analyze later on in this article.
How to join?
Contributors to the DZ network need minimum requirements of:
- Dedicated bandwidth that can provide IPv4 connectivity and an MTU of 2048 bytes between two data centers
- DoubleZero Device (DZD) hardware that is compatible with the DoubleZero protocol
Clearly these participants are not the “home stakers” that Ethereum targets.
Has this been attempted before?
The ideas behind DoubleZero are not new or revolutionary. It can be thought of from two separate perspectives:
- optimizing blockchains by bringing tradfi HFT machinery
- specializing CDNs to the blockchain context (eg. compare to cloudflare 2-ring architecture for email delivery)
The internet is simply said, a network of networks. And DoubleZero is attempting to join as one of the networks. What’s unclear to me is how exactly it will present itself to the rest of the internet. It seems like they have plans to present themselves as public ASN 21682, similarly to how Cloudflare presents itself to the internet using ASN 13335. They still are currently private and don’t participate in BGP as far as I’m aware.
Architecturally speaking, the separation into two “rings” is more marketing than substance. It makes perfect sense given that those two rings are functions that need to be performed by everyone blockchain already. The Ethereum mempool is an outer ring. Cosmos has long ago presented the idea of using sentry nodes as an external “ring”.
As for the internal ring, all that it is is a performant multicast network to physically optimize Turbine (or Rotor post Alpenglow) propagation of blocks. I cannot speak to the actual implementation, but at least on paper it feels very very similar to BloXroute, which presented in 2018 a whitepaper announcing a bitcoin and ethereum blockchain delivery network (BDN) to speed up transaction and block delivery.
Interestingly, the BLXR token mentioned in the whitepaper never seems to have been launched, yet BloXroute is still around 7 years later, with one of their main product offering now being… Paladin, an MEV solution for Solana. I would hypothesize that we will see DoubleZero follow a similar trajectory, because the only value in BDN seems to be from MEV extraction. I do not see how beneficially filtering txs for the greater good of the network can be commercially viable. As for the doublezero token, all that I can say is that I hope it will perform better than BloXroute’s EGL.
Bullish case for DoubleZero
Austin Federa mentions in this interview that the firedancer demo at Breakpoint 2024 showing 1m tps with 6 nodes on 4 continents, was running on the DoubleZero network. Jump is developing the firedancer client, and Andrew McConnell used to be Head of Infra at Jump. A lot of things seem to line up here, as if DoubleZero was incubated from a need that emerged out of the development of the firedancer client.
In a similar vein, SIMD-110 was a very controversial Solana proposal to add an eip1559-like mechanism to Solana to create economic backpressure, at a moment when spam was at an all time high and normal users could hardly land any transactions, even when paying high priority fees. The debate arguments in the proposal are quite informative and worth a read. Most people against the proposal argue that “all we need is fatter pipes, faster filtering, a better scheduler, and to let the free market of local fees work its magic.” The simd was closed and I am not quite sure what became of it, but if anything, doublezero is bringing the hardware pipes needed to allow the local fee markets (LFMs) to work their magic and let solana rip.
Bearish case for DoubleZero
An unfortunate but not necessarily unlikely scenario for DoubleZero is that it’ll end up like most (all?) DePIN projects out there: with no demand side to meet its supply side. Once the token incentives will dry out, the network will completely vanish.
The usecases for the doublezero filtering and multicasting primitives are clear. The question is whether they are worth the cost for the demand side. The other side is whether they are worth the risk for the supply side (what happens if an SLA is not met is still unclear based on all of my readings).
Another larger industry-wide bearish case for DoubleZero is if the entire “decentralized NASDAQ” driving force behind Solana collapses, as the market realizes that even with multicast primitives, global consensus is too expensive to pay, and blockchains can’t compete with RDMA-based LANs that have fairness inducing speed bumps (albeit not without their controversies).
Another question is how large their TAM really is. If they do try to target other blockchains, will their protocol generalize well enough to the different architectures (for example multi leader DAG based sui and aptos protocols)? And are they going to have to maintain protocol specific FPGA implementations? Scaling typically requires having products that can generalize to other domains. Will they branch out and become a generic CDN like Cloudflare?
On the more technical side, DoubleZero is pushing for IBRL optimality by for example routing via latency minimizing paths as opposed to turbine’s stake weighted paths. This is fine in trusted environments, but goes against the principle of censorship resistance that blockchains are trying to achieve. Turbine’s entire point behind stake weighted paths is that it is hard to censor at the top of the tree if each block chunk is sent following a different spanning tree. How is doublezero going to protect against malicious and/or greedy switch contributors who might decide to favor their validators? Networking monitoring for faults is a non-trivial problem, and its very unclear to me that it can be made to work in a decentralized fashion.
Similarly, they currently advertise as a single ASN, which means they plan to use a single routing policy throughout the DoubleZero network. That works for multicast, but it doesn’t work for other p2p primitives or unicast tx ingestion. Who will dictate the routing policy? Is it going to be controlled by the DoubleZero foundation? The internet uses BGP because it encodes business relationships instead of optimality, why should blockchain routing work differently? After all, business agreements also trump tradfi, with Citadel buying Robinhood’s order flow in bulk. Practically, BGP picks the CHEAPEST, not the shortest path (mostly because in “NO WALLA OMNI,” “A” is way after both “W” and “L”). Can DoubleZero do better? Tim Griffin would say… probably not.
Whitepaper Quotes
We will analyze a few snippets from the whitepaper, broken down into 4 main topics: network layer, architecture, TAM/other usecases, and bft/governance.
Network Layer
“The key to unlocking higher performance for these systems is to optimize data flows”
Minimizing data movements is indeed the key, and its refreshing to hear this perspective in a blockchain context.
Forgetting about networking for a second and zooming in to a single machine, optimizations like core-per-thread, zero-copy, DMA are necessary to achieve high levels of performance. Even at the single chip level dataflows are important! Groq’s latest AI GPU chip was designed from the ground up by ex Google TPU engineers to optimize dataflows.
So its not very surprising that at the WAN level dataflows would have a large impact on overall performance. If read lock contention on a numa architecture is already bad for performance, then of course data flowing between machines distributed around the world is even more paramount to optimize. At the end of the day, speed of light is the one constraint that we can’t engineer our way out of.
The one thing to keep in mind however, with respect to Solana’s mission to “decentralize NASDAQ”, is how a WAN network like DoubleZero can compete, on a fairness level, with a collocated system using Infiniband (reliable > best-effort delivery), Ethernet multicast (> IP multicast over tunnels), and IEX-like fiber coil speed bump.
“The physical network layer that blockchains use has not changed since the advent of Bitcoin. […]”
This isn’t entirely true. I am not aware of the specifics, but at the very least BloXroute was there way before them, and a comparison with BloXroute is not presented or even acknowledged anywhere.
On a more fundamental level, physical links and layer 1 and 2 technologies are constantly improving and the entire planet, including of course blockchains, is benefiting from this. Nielsen’s Law is already providing 50% growth per year to high end users’ connection speeds, and DoubleZero is not going to change that.
Separately, DoubleZero likes to say that its a physical network living at the OSI levels 1 and 2. This is quite a bit of a stretch, since DoubleZero in reality lives at a much higher-level. It is really a marketplace, scheduler, router, and admonisher of penalties. DoubleZero does seem to provide its own switches for peering its contributors, but its real function is really to monitor those contributors and make sure they meet their SLAs.
Also, Bitcoin has long ago moved participants running ASICs and a lot of them aggregating into mining pools. These mining pools with (semi?) trusted participants no doubt already use LLHB (low latency high bandwidth) connections. I wouldn’t be surprised to learn that some of the major mining pools have networking facilities as sophisticated as DoubleZero’s.
DoubleZero Architecture
“First, inbound transactions can be edge-filtered (i.e. removed of spam and duplicates) by specialized hardware”
Unclear what they mean by “edge” here, since the diagram above shows that filtering is colocated and done on each validator. If this was truly done at the “edge” like Cloudflare does, then censorship resistance would fall.
So then let’s assume that their “edge” actually means “colocated next to each validator”. In such a case, I fail to see how this is not already the case, since any validator that wants to extract MEV effectively needs to filter the chaff from the wheat, and the highest staked validators that are getting bombarded by txs no doubt are already using specialized hardware/services to do this filtering. Case in point, Solana’s whitepaper already mentioned using GPUs for ECDSA signatures.

Note that this is very outdated, as Solana uses ED25519 instead of ECDSA. Furthermore, as far as I understand, GPUs have never been used in practice because of the data movement latency incurred (dataflow once again showing its importance).
However, FPGAs do not incur this batching cost, and firedancer’s wiredancer is already using AWS F1s to verify signatures (and a PR to support F2s is in the making).

Perhaps DoubleZero plans to hardcode that logic into ASIC circuits? That will be very hard to do for a product that markets itself as being protocol agnostic. The same ASICs could not be used to verify Ethereum BLS or ECDSA signatures.
“By placing FPGA appliances to filter inbound traffic at key ingress points at the network edge, the DoubleZero network acts as a common shield for all local validators”
This makes sense in theory. People are used to putting Cloudflare in front of their apps to protect from L4 DDoS attacks or even for some form of L7 filtering via WAF rules. The doublezero FPGA program would probably run the typical solana dedup/sig-verify/fee-check pipeline.
The need for this inbound filtering was already discussed in extreme depth in the simd-110, with the main argument from proponents of that proposal that a form of economic backpressure was needed to prevent overwhelming the ingestion pipeline, and preventing valuable txs from reaching the scheduler in time. However, many people argued that fatter pipes and a better scheduler was all that was needed, and simd-110 was eventually closed. This indicates that the filtration pipeline might be doing fine these days, and that fpgas might not be needed? Or perhaps all validators are already running fpgas? I would like to see more data-driven reasoning around the need for this.
Other Usecases for the DoubleZero Network
“Outside of the blockchain world, content delivery networks, gaming applications, large language models, and enterprise users can benefit from the network for similar reasons.”
Interesting that they don’t mention tradfi trading. Probably because they know that HFT firms already have leased lines and lowest latency routes for trading among exchanges.
But so do all of the other examples mentioned. Netflix and other content providers are already peered with ISPs all around the world. IPTV already uses multicast where needed (although fun fact Netflix streaming does not). LLM training, even if spanning multiple datacenters, only spans a single governance org, which no-doubt already has their own fiber to connect their different datacenters. As for gaming, let’s look at this next quote.
“Some games use peer-to-peer models, whereby the end players connect directly over the public internet. OatmealDome offers a particularly detailed description of Splatoon as an example of this. […] The DoubleZero network, with its dedicated links and its flexible usage model, can deliver stability to the connections and make the games more enjoyable”
As always, the devil is in the details. Taking snippets from the blog post:
- “The game and netcode ticks at 60Hz. However, packets can only be sent every 4 ticks. This results in an artificially constrained packet send tick rate of 15Hz.”
- “Why is Nintendo artificially constraining the tick rate? This is likely for bandwidth reasons, as Octobyte stated. According to their data, there was a 45% reduction in bandwidth going from Splatoon 1 to Splatoon 2. It could also be for stability reasons. By using less data, it can allow players with less capable Internet connections to be able to play online. This is especially beneficial for mobile hotspots.”
This last sentence is the most important. It is very often the case that last-mile latency is the most significant. A backbone network like doublezero cannot help eliminate this problem, as it only connects the major datacenters where blockchain validators are hosted.
As a side note, the 15Hz send rate limitation shows Nintendo prioritizing bandwidth efficiency over responsiveness. Note how responsiveness is more important than latency! That is to say, if network latency only considers the pipes and routes, responsiveness considers the entire request-response time, including host server processing time. This distinction is less important in a blockchain p2p context, but is very important for all other application domains that are more client-server centric.
“It is difficult to colocate large numbers of GPUs in a single facility and align their spare capacity, and so large tech firms have designed systems to coordinate asynchronous and distributed resources such that they can train unified models, e.g. Gangidi et al[2024].”
It might be difficult but collocation is such a massive advantage that literally every FAANG is currently rushing to build its GW datacenter (see also this).
Distributed training of huge scale models requires RDMA, which currently runs on 3 different technologies: Infiniband, RoCE1/2, and iWARP. Infiniband has its own proprietary link layer, so could not be tunneled over the doublezero network. RoCE2 and iWARP potentially could, but unclear what the efficiency losses of transporting using GRE would be. Plus all companies doing distributed training already have their own dark fibers and networking engineers.
“If we disintermediate the filter and execution rings to provide more flexibility, we can distribute ingress resources more efficiently and more resiliently”
Disaggregation is a very hot topic, and is happening all over computer science. Databases are being dissagregated thanks to cloud object storages like S3. Networking has already seen it happen thanks to SDN disaggregating the control and data planes.
Yet, in the case of filtering and execution, there is a big elephant in the room, and that elephant is called MEV. The filtering happening here is not only dumb l4 filtering. Filtering also means having access to the txs in the first place. And in finance, order flow IS the money, and is typically kept private. Meaning that my guess is that most of the txs getting filtered are probably not very valuable. So a tragedy of the commons phenomena will likely happen, with validators running these expensive FPGAs to filter through low-value txs soon enough questioning the value they are getting out of providing this service.
In fact, DoubleZero already offers an IBRL mode which doesn’t run the filtering ring.
“Further optimization of traffic flow is achieved by support for multicast traffic on the inner ring of the DoubleZero network”
Optimizations always sound good until you realize that a blockchain is supposed to be tolerant to Byzantine behaviour. By making contributor routers optimize traffic, how do we make the protocol byzantine resistant to their behavior…? Multicast is not supported on the internet for this very reason. How does the doublezero network prevent DDoS attacks? Is it forever going to remain permissioned?
They also have a recent blogpost that expands on the transition from Turbine to Multicast block propagatin: “Unlike Turbine, multicast aggressively optimizes block propagation on Solana around geography and specialized hardware.”
There is one key sentence in the blog post: “Multicast turns the network from passive to active infrastructure, on two dimensions”. This sounds like a panacea, with routers doing work for the validators, but is also a huge problem in a chain that is supposed to be byzantine fault tolerant. The link and switch contributors to the DoubleZero network are not the massive public set of internet routers that they are on Solana today, and which couldn’t care less about the Solana traffic that is going through their pipes. They are the Jumps of the world, a very small set of active market participants, which are also very likely running validators themselves and trying to extract MEV. I am not knowledgeable enough about how financial market dynamics work in general, but have a feeling the DoubleZero network dynamics might somehow look like those of the MetaAI SuperIntelligence team drama.
BFT and Governance
“this is all done via open-source software that can be inspected to ensure fair treatment of inbound transactions”
That is not how BFT works. I can inspect the Bitcoin core client, or any Solana client, but the whole point of a Byzantine fault tolerance is that validators cannot be assumed to be running the audited code.
“Performance of the links is monitored and tested by the DoubleZero network to ensure compliant links are eligible to earn rewards, while non-compliant links may be disqualified for rewards and potentially removed from the network.”
This is some major handwaving. Data Availability Sampling (DAS) already has its fair share of open problems. DePIN observability and monitoring is as far as I know even harder of a problem, and monitoring a networking layer like doublezero sounds like the hardest of the DePIN problems. My guess is they will start with centralized governance, and will eventually have to solve the “who watches the watcher” question, with typical solutions all having issues:
- Self-monitoring: Participants can lie about their own performance
- Peer monitoring: Collusion between participants
- External oracles: That’s just adding one more layer of turtles
- Statistical consensus: Sybil attacks and coordinated deception
“As an illustration, a network contributor for a link from Los Angeles to Singapore may commit to 10 GBps at 85ms latency with 1600 MTU.”
In order to commit to any sort of latency based SLA, the contributor needs to control that pipe and not be multiplexing it with anything else. Who other than FAANG and 5 largest telecom providers own such a link? Would the SLA written onchain look like this?

What kind of punishment would it get for breaking its SLA? Most ISPs do not take transit SLAs very seriously, why should it work differently here?

“As inputs come in, the distributed controller uses smart contract data to identify the optimal configuration for the network”
Why does the configuration data need to live on a blockchain if the controller is what matters?
Configuration data is typically very important, and hence tends to be written on linearizable datastores. One can debate what kind of consistency guarantees blockchains give to reads, but one thing certain is that blockchains are not linearizable.
As for the controller, let’s note that is it very likely distributed, but not decentralized. Meaning that it might run on multiple machines, but is very likely running under a centralized governance. There lies the issue. The whole point of BGP and ASs is that different ASs don’t agree on internal routing policies. I fail to see how DoubleZero participants will agree to a single routing policy. Furthermore how will it itself be controlled? The whitepaper lacks in details.
“A system of checks and balances, based on the same cryptoeconomic values that secure proof-of-stake networks today”
Doublezero sounds like they are trying to have their cake and eat it too. Either you have POS which is a shitty governance model, or you have proof-of-governance like oversight. And this is the fundamental tradeoff that I don’t see them answering anywhere.
They also claim to solve problems with mempools, but fundamentally economically they are just an optimized mempool + block propagator. Mempools are fundamentally economically broken in my mind, because private order-flow is where the money lies.

They also seem to have changed their direction regarding PoS and are now saying they will implement Proof of Utility in a recent blogpost.
- “Rather than hewing to traditional PoW or PoS models, DoubleZero implements ‘Proof of Utility.’ Rewards are paid out in proportion to useful work done, above and beyond the work done by other participants, which ensures the protocol remains dynamic over contribution type and contribution time.”
The blogpost also lacks a lot of details unfortunately. PoU is about using a Shapley Values to reward network contributors based on usage, and they point to their github repo implementation. The part that I don’t understand is that usage is determined by routers, and it’s unclear to me how those are set and governed. Who manages the control path, controls the token rewards.