BFT Broadcast
March 16, 2026
Broadcast is a very useful distributed systems primitive. It is often presented as a building block which is combined with an agreement protocol to achieve State Machine Replication (SMR) - what modern blockchains call “consensus”, and in theory is also confusingly called total-order or atomic broadcast.
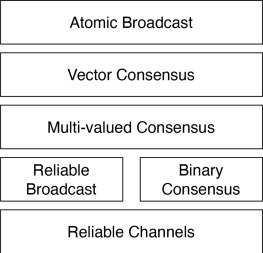
Yet, perhaps adding to the confusion, broadcast and agreement (binary consensus) can be proven equivalent. What the…
Terminating Broadcast vs Binary Consensus
Distributed system problems are typically defined in terms of the liveness and safety properties that their solutions must respect. We follow the definitions from here, but qualify “Broadcast” as “Terminating Broadcast” to prevent confusing it with other forms of broadcast (see section below). Note that we also rename the “agreement” property to “consistency”.
First we note that both of them have the exact same consistency (safety) and termination (liveness) properties:
- (agreement): no two honest nodes decide on different values.
- (termination): all honest nodes must eventually decide on a value in V and terminate.
Hence they really only differ in their validity (safety) requirement:
- Agreement (binary consensus): if all honest nodes have the same input value v then v must be the decision value.
- Terminating broadcast: if the leader is honest then v must be the decision value.
The blog post then goes on to show that this difference is not meaningful and both problems are equivalent, in the sense that a solution for one can be used to solve the other.
Broadcast Liveness Hierarchy
Terminating broadcast and binary consensus being equivalent means that both of them are subject, under asynchrony, to the FLP impossibility result, meaning that they cannot be solved using a deterministic algorithm.
Nevertheless, broadcast as a concurrent object has a property which differentiates it from agreement: it is a single-writer object, as opposed to a multi-writer object. Indeed, note how broadcast’s validity condition above only talks about the leader being honest. This allows weakening its liveness requirements, while still retaining a useful primitive1.
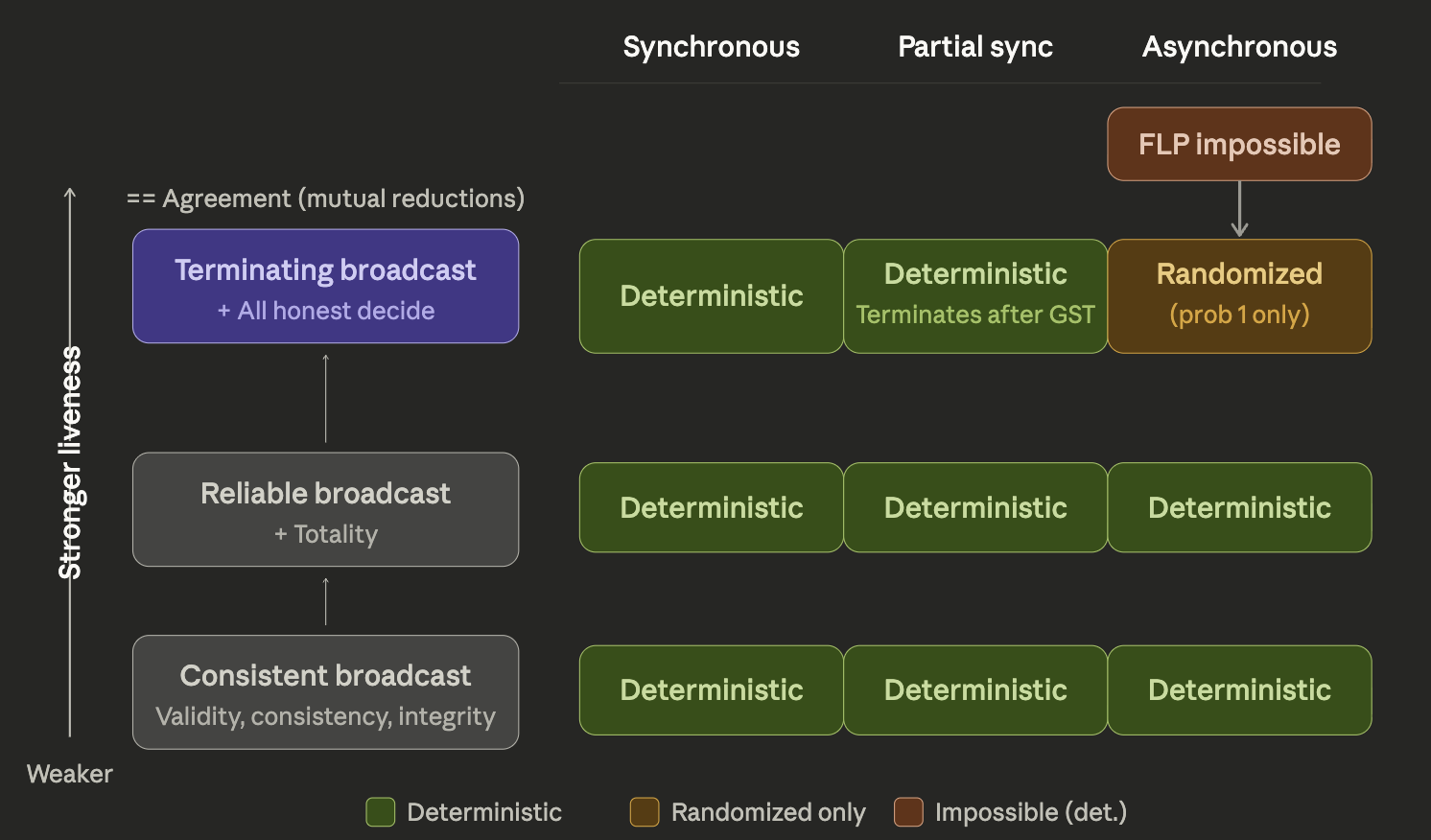
Cachin’s Byzantine Broadcasts and Randomized Consensus notes very precisely walk through these different models, explaining their differences. Succinctly put, the difference between consistent, reliable, and terminating broadcast is just the requirement on whether/when honest nodes are forced to (eventually) output a value.
| Broadcast | Honest Nodes Termination Guarantee |
|---|---|
| Terminating | Always (even with faulty leader) |
| Reliable | Honest leader OR if any one honest node terminates |
| Consistent | Honest leader |
In consistent and reliable broadcast, honest nodes are allowed to never output any value when the leader is dishonest.
Also worth noting the similarity with the CAP tradeoff, where we trade consistency (some nodes not terminating) for liveness.
Solutions for CB and RB
Consistent Broadcast (CB) and Reliable Broadcast (RB) are super easy to achieve with a public-key setup, even under asynchrony.
// Leader S with input b
send <propose, b>_S to all parties
// Party i (including the leader)
on receiving the first proposal <propose, b>_s from leader:
send <vote, b>_i to all parties
on receiving <vote, b>_* signed by n-t distinct parties:
// uncomment this line to achieve Reliable Broadcast
// forward <vote, b>_* signed by n-t distinct parties to all parties
commit b
This reliable broadcast implementation is detailed in this blog post which then goes on to augment it to achieve terminating broadcast.
Asymmetric crypto and Broadcast Setup
Some protocols (like Bracha’s reliable broadcast) only require pairwise authenticated channels, which can be implemented with symmetric cryptography only2. Moving past that and requiring asymmetric crypto and a public-key distribution setup (aka a broadcast setup), has two major benefits:
- Lower message complexity — Cachin’s notes compare two consistent broadcast implementations. Reiter’s Echo Broadcast routes through the sender for O(n) messages instead of O(n²) in Toueg’s authenticated broadcast. But this trades latency for messages (3 steps instead of 2) 3.
- Transferable certificates — This is the big one. Without signatures, when you see n−f echoes, you know there’s agreement but you can’t prove it to someone who didn’t see those echoes. With signatures, you can package the evidence and hand it to anyone. This is what we used in the RB implementation above.
Signatures don’t help with round complexity of broadcast in isolation. They help with composability — making broadcast outputs useful as inputs to subsequent protocol stages. That’s why they’re essential for SMR but not for standalone broadcast.
View change triggers
A consequence of transferable certs (#2 above) is that we can construct efficient view changes, which are necessary for achieving termination guarantees when broadcast instances start with a faulty leader.
For example, in partial synchrony protocols, when you change leaders, the new leader needs to learn what might have been committed. With certificates, a new leader collects lock-certificates from n−t parties and can prove its proposal is safe. Without signatures, the new leader has to take parties’ word on trust, which creates much harder protocol design problems.
Asynchronous protocols tend to work differently, but can still be explained in similar terms.
| Model | What drives round advancement | How faulty leaders are handled |
|---|---|---|
| Sync | Timer (known $\Delta$) | Fixed schedule; protocol survives by design ($f+1$ rounds) |
| Psync | Timeout (estimated $\Delta$) | Abandon and rotate to next leader |
| Async (ACS) | Message counting ($n-f$ deliveries) | No single leader; everyone broadcasts |
| Async (DAG) | Message counting (enough vertices) | DAG keeps growing; coin retrospectively picks anchors |
Sync: Rounds advance by known $\Delta$ — everyone moves to round $r+1$ after $\Delta$ time. There’s no leader to abandon because the protocol just runs for $f+1$ fixed rounds. The timer isn’t a trigger for recovery, it’s just the clock that drives the protocol forward.
Psync: You wait for the leader’s proposal, and if it doesn’t arrive within some timeout (which may increase over time with exponential backoff), you vote to move to the next view. The key property is that after GST, the timeout will eventually be large enough to accommodate actual network delays, so an honest leader will succeed.
Async: Randomness doesn’t trigger a view change the way timeouts do. There are really two different patterns:
- In ACS-style protocols (HoneyBadger), you don’t have leaders at all. Every party RB-broadcasts its own batch, and then $n$ parallel binary consensus instances (using random coins) decide which batches to include. The coin breaks FLP symmetry within each consensus instance. There’s no view to change — progress happens when the coin aligns with the majority vote.
- In DAG-based async protocols (DAG-Rider, Tusk), you keep building the DAG continuously. Nobody ever “abandons” a round. The random coin is used retrospectively — after enough DAG rounds accumulate, a coin determines which vertex becomes the anchor, and everything in its causal history gets committed. A faulty “leader” doesn’t stall anything because the DAG keeps growing regardless.
Conclusion
We have explored the bottom left part of this Broadcast cheat sheet.
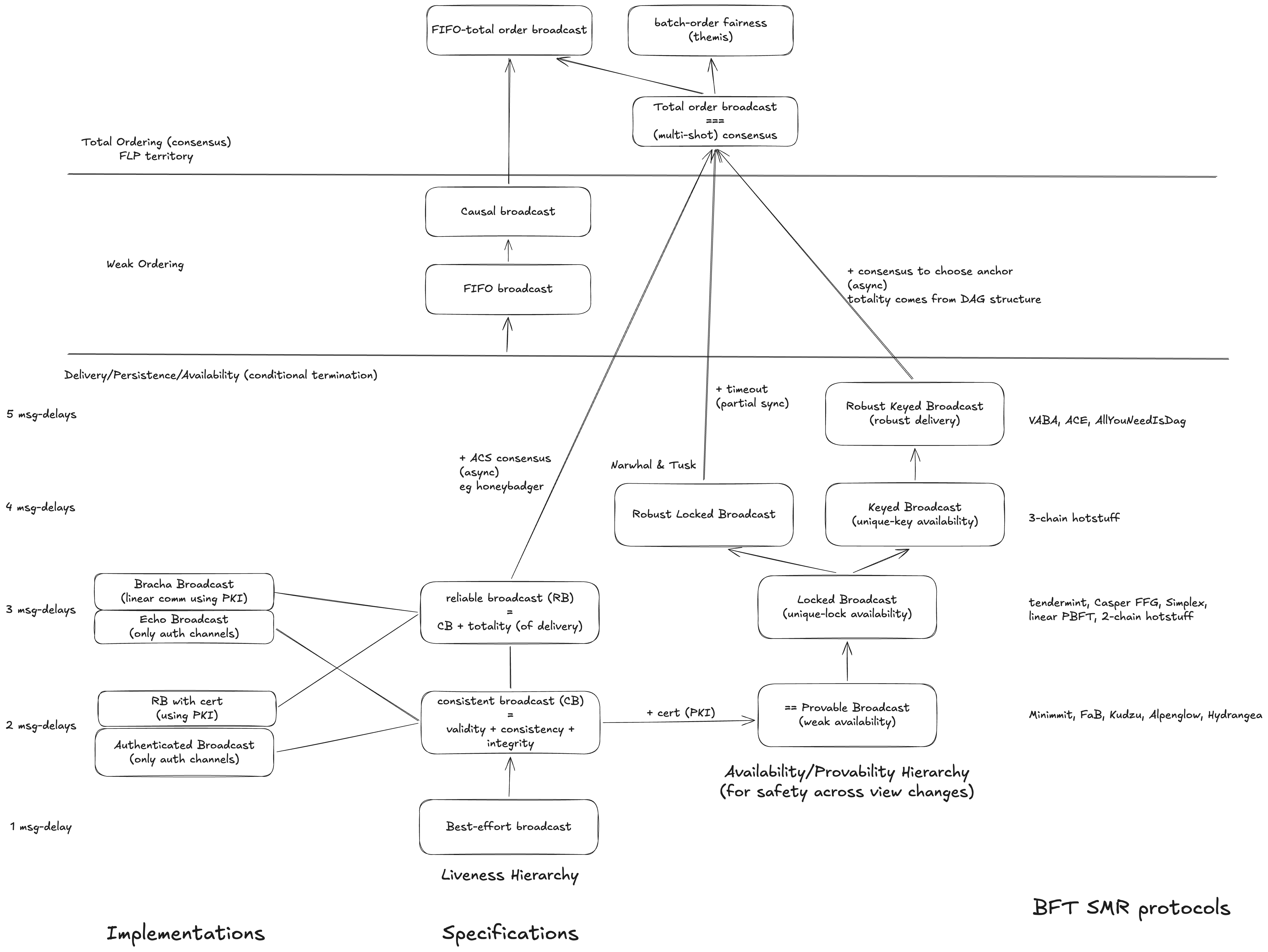
Next Steps: Provability Hierarchy
With a better understanding of the various broadcast primitives under our belt, we are now ready to go back to the original question at the beginning of this article: how are broadcast and consensus primitives put together to achieve SMR/atomic-broadcast protocols? A very interesting way to answer this question is via the perspective of Provable Broadcast (PB) – which just means broadcast implementations that make use of asymmetric crypto to create certificates.

PB is not a specific protocol — it’s a specification that says “CB/RB + a transferable certificate.”
- PB built on CB (e.g., Echo Broadcast / Reiter): 2 message steps, no per-instance totality, you get a certificate
- PB built on RB (e.g., Bracha-style): 3 message steps, per-instance totality included, you get a certificate
And then the entire availability tower — Locked Broadcast, Keyed Broadcast, Robust Keyed Broadcast — is built by chaining PBs. Each PB in the chain can independently be instantiated with CB or RB underneath.
The design choice DAG protocols face is: do you want totality baked into every PB instance (use RB, pay 3 steps), or do you want to handle totality structurally at the DAG level (use CB, pay 2 steps, add pull mechanisms) 4?
References
- https://dcl.epfl.ch/site/_media/education/sdc_byzconsensus.pdf
- https://decentralizedthoughts.github.io/2020-09-19-living-with-asynchrony-brachas-reliable-broadcast/
- https://decentralizedthoughts.github.io/2020-09-14-broadcast-from-agreement-and-agreement-from-broadcast/
- https://decentralizedthoughts.github.io/2025-02-14-partial-synchrony-protocols/
Footnotes
-
It also allows tolerating more faulty nodes, but this is out of scope for this blog post. ↩
-
Main benefits of this approach are faster crypto and post-quantum safe aggregation (although there are approaches that will make this possible). ↩
-
Personally think the linear communication complexity card is way overplayed by theoreticians. See The Pipes Model for Latency and Throughput Analysis for an imo more useful model. ↩
-
The pipes paper has a partial answer to this, in its Corollary 1 section: “Corollary 1 is already cubic in n in the case that metadata is Θ(n), while if metadata in the single-sender case is of constant size then the corresponding term in the single-sender case is O(n). Perhaps to avoid these issues, practical instantiations of DAG-based protocols tend to use a form of CB rather than RB for the purposes of block propagation.” ↩